









 CEO Microsoft Satya Nadell
CEO Microsoft Satya Nadell

Россия по темпу внедрения ИИ в экономику оказалась на уровне Африки. Что, впрочем, совершенно неудивительно.
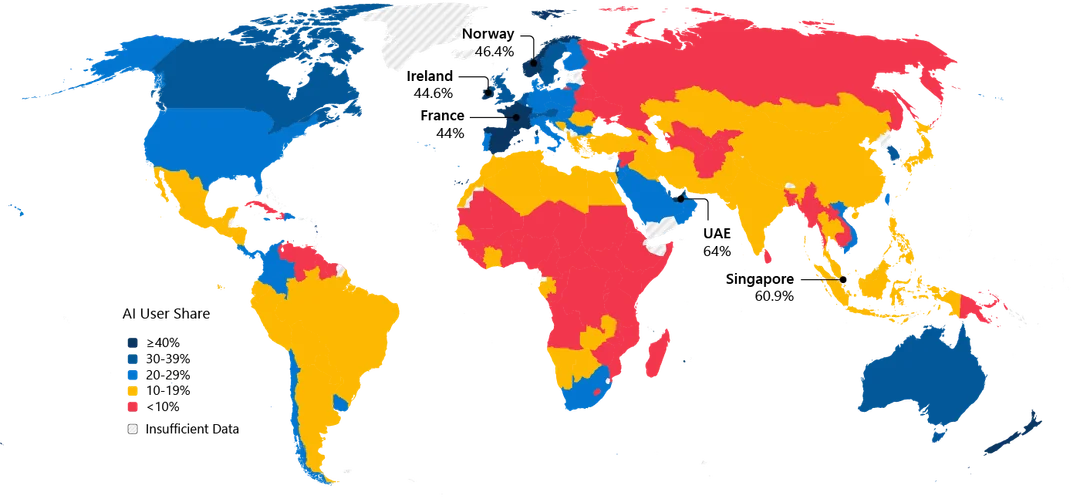
Россия заняла 119 место в мире по темпам внедрения искусственного интеллекта (ИИ) в экономику. Это показало исследование Института экономии ИИ Microsoft, которое было проведено по итогам 2025 года. Согласно расчетам аналитиков, в первой половине года 7,6% россиян трудоспособного возраста использовали ИИ для решения рабочих задач, а во второй — 8%. Таким образом, рост составил 0,4 процентного пункта.
Для сравнения: в ОАЭ, которые являются мировым лидером по внедрению ИИ, число пользующихся нейросетями жителей достигло 64% (рост на 4,5 п.п.), во Франции — 44% (3,1 п.п.), в Германии — 28,6% (2,1 п.п.), а в США — 28,4% (2,1 п.п.). Обошли Россию по этому показателю Иран (10,7% населения, рост на 1,1 п.п.), Китай (16,3%, рост на 0,9 п.п.), Беларусь (8,4%, плюс 0,8 п.п.) и Венесуэла (9%, плюс 0,7 п.п.). С текущим показателем Россия находится примерно на одном уровне с африканскими странами — Кенией (8,1%, прирост за год 0,3 п.п.), Камеруном (7,8%, на 0,7 п.п.) и Центральноафриканской Республикой (7,8%, на 0,7 п.п.).
При этом абсолютным лидером на российском рынке стала китайская модель ИИ DeepSeek. По итогам 2025 года она заняла долю 43%, тогда как у ближайшего конкурента ChatGPT — около 40%, у GigaChat и Qwen — 6%, а у «Алиса AI» (ранее YandexGPT) — порядка 5%. Как отмечают в Институте экономии ИИ Microsoft, помимо Китая и России, наибольшее распространение DeepSeek получил в Иране, Беларуси, на Кубе и в Африке.
Ранее президент РФ Владимир Путин обвинил западные ИИ-системы в русофобии и ангажированности. Он подчеркнул, что их доминирование на российском рынке недопустимо. По словам Путина, алгоритмы способны «отменять» российскую культуру, игнорируя вклад страны в науку, искусство и литературу. В ответ на это он призвал развивать отечественные технологии ИИ, основанные на «традиционных ценностях».
При этом России практически нет на мировом рынке ИИ. На русскоязычном сайте платформы LM Arena, где пользователи оценивают модели нейросетей, лучшие российские варианты — GigaChat от «Сбера» и «Алиса AI» — не входили в топ-20. Согласно рейтингу Стэнфордского университета Global AI Vibrancy Tool, который был выпущен в ноябре 2025 года и измеряет развитость и эффективность ИИ-экосистем, Россия занимает 28-е место из 36 стран.
«Россия на годы отстает в разработке собственного ИИ. Она уже проиграла в этой гонке, и догнать [лидеров ей] невозможно», — говорил The Wall Street Journal Юрий Подорожный, который в прошлом возглавлял службу разработки сервисов «Яндекс.Карты» и «Яндекс.Метро». (Отсюда.)
Тем не менее рано грустить по этому поводу, потому что России есть куда развиваться в области развития искусственного
РКН планирует создать механизм фильтрации интернет-трафика на основе ИИ
Роскомнадзор (РКН) намерен в 2026 году создать и внедрить систему фильтрации интернет-трафика с помощью технологий машинного обучения, пишет Forbes. На эти цели в ведомстве планируют направить 2,27 млрд руб., следует из плана цифровизации РКН.
По информации издания, документ уже направлен в правительственную комиссию по цифровому развитию. Согласно нему, новый механизм будет работать на базе уже действующих в сетях операторов технических средств противодействия угрозам (ТСПУ), которые обеспечивают фильтрацию по технологии DPI (Deep Packet Inspection, глубокая фильтрация трафика по содержимому пакетов). С их помощью уже заблокировано более 1 млн ресурсов, а также ежедневно ограничивается доступ к 5,5 тыс. новых адресов. (Отсюда.)








