Новая технология улучшения изображений от Google
Я неоднократно читал о различных технологиях улучшения изображений и вообще за этими разработками стараюсь следить - это очень важно и будет востребовано.
Сейчас корпорация Google объявила о создании новой технологии улучшения изображения, повышающей разрешение картинки аж в 16 раз. Цитирую отсюда.
Разработчики Google представили новую технологию, благодаря которой можно значительно улучшить качество исходного изображения. Искусственный интеллект попиксельно восстанавливает даже сильно сжатую картинку, приближая её к оригиналу.
Команда Brain Team продемонстрировала два алгоритма генерации фотографий. Используя технологию SR3, предусматривающую апскейлинг с помощью повторного уточнения, нейросеть увеличивает разрешение картинки, достраивая недостающие части из гауссовского шума. Обучение этой модели построено на методах искажения изображения и последующем обратном процессе.
Вторая диффузная модель — CDM. Для её обучения специалисты использовали миллионы изображений в высоком разрешении из базы данных ImageNet. Улучшение качества картинки она производит каскадно — в несколько этапов. Так, исходник размером 32х32 пикселя улучшается до 64x64, а затем до 256x256 (в 8 раз), а оригинальное изображение с разрешением 64x64 точки обрабатывается по схожей схеме до 256x256 и 1024x1024 пикселя (масштабирование 16x).
По заверению разработчиков, новая технология превосходит по качеству восстановления фотографий такие современные методы ИИ-масштабирования, как BigGAN-deep и VQ-VAE-2.
На сегодня Google лишь продемонстрировала результаты работы алгоритмов посредством коротких анимаций, но ещё не публиковала подробностей о новой технологии. Когда компания планирует представить коммерческий вариант ИИ-апскейлера, не уточняется.



Выглядит это все очень интересно, но, как обычно, буду ждать, когда предоставят готовый инструмент, с помощью которого я смогу посмотреть, как это работает вживую.
Главное приложение этой технологии - видеоконференции через (в основном) мобильные приложения. Вы, когда делайте видеозвонки через facetime, WhatsApp, Telegram, Signal, etc - вы видели сколько они данных жрут, особенно в хорошем разрешении? Посмотрите - час видеосвязи через wifi - 1.2 гигабайта. Причем 100% заряженная батарея просядет на 60% или больше.
А с этим - нужно передавать фото/видео высокого разрешения только в начале, чтобы нейронная сеть в телефоне (ага, в телефоне есть свой AI chip) начала train & optimize. Через минуту две, разрешение можно снизить 4 раза, объём передаваемых данных - в 10 раз и вся нагрузка будет на AI чип на принимаемой стороне чтобы восстановить исходное изображение.
Думайте это только гугл в этом замешен? Во Nvidia еще в прошлом году выпустила прес релиз
Maxine's video compression uses a generative adversarial network (GAN) on the receiver side to reconstruct images of human faces from the position information of only a few key points taken from the sender's images. By sending only these points, instead of pixel data, the bandwidth requirements are drastically reduced compared to the H.264 compression standard, by up to 10x. Maxine also provides several other features, including face alignment and animated avatars.
NVIDIA's AI Reduces Video Streaming Bandwidth Consumption by 10x
Запахи давно уже симулируются и улучшаются химически.
Вкус? Ну, разные глютаминаты натрия давно уже как. Не говорю про соль с сахаром. Ничего, скоро будет "Официант! Две пилюли с черной икрой, две с красной, а бифштекс мелко измельчить".

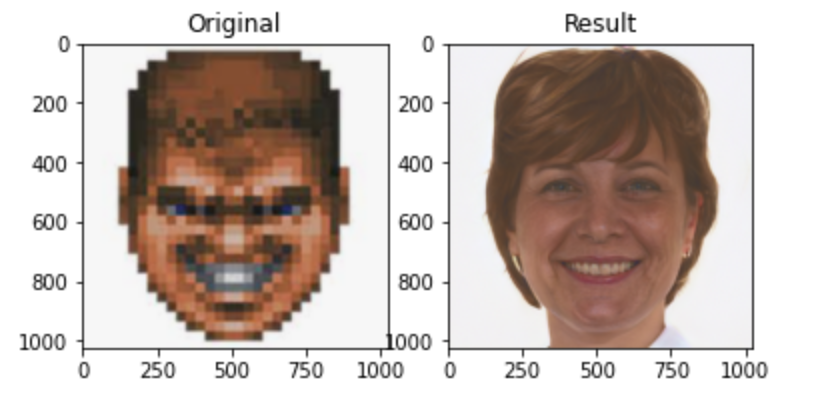
И что за красная штучка над правым ухом у мужика?
Откуда?
Но может порой сильно нафантазировать - несколько пятен в темноте он превратил в группу людей. 😄
Но в целом, программа очень хороша и хороша, помимо увеличения изображений, для очистки их от артефактов сжатия.
А Топаз работает вот так:


P.S. Возможно, что-то там когда-то там у вас и получилось лучше топазовских программ – но на сегодня они одни из лидеров в этом направлении. Просто объективно.
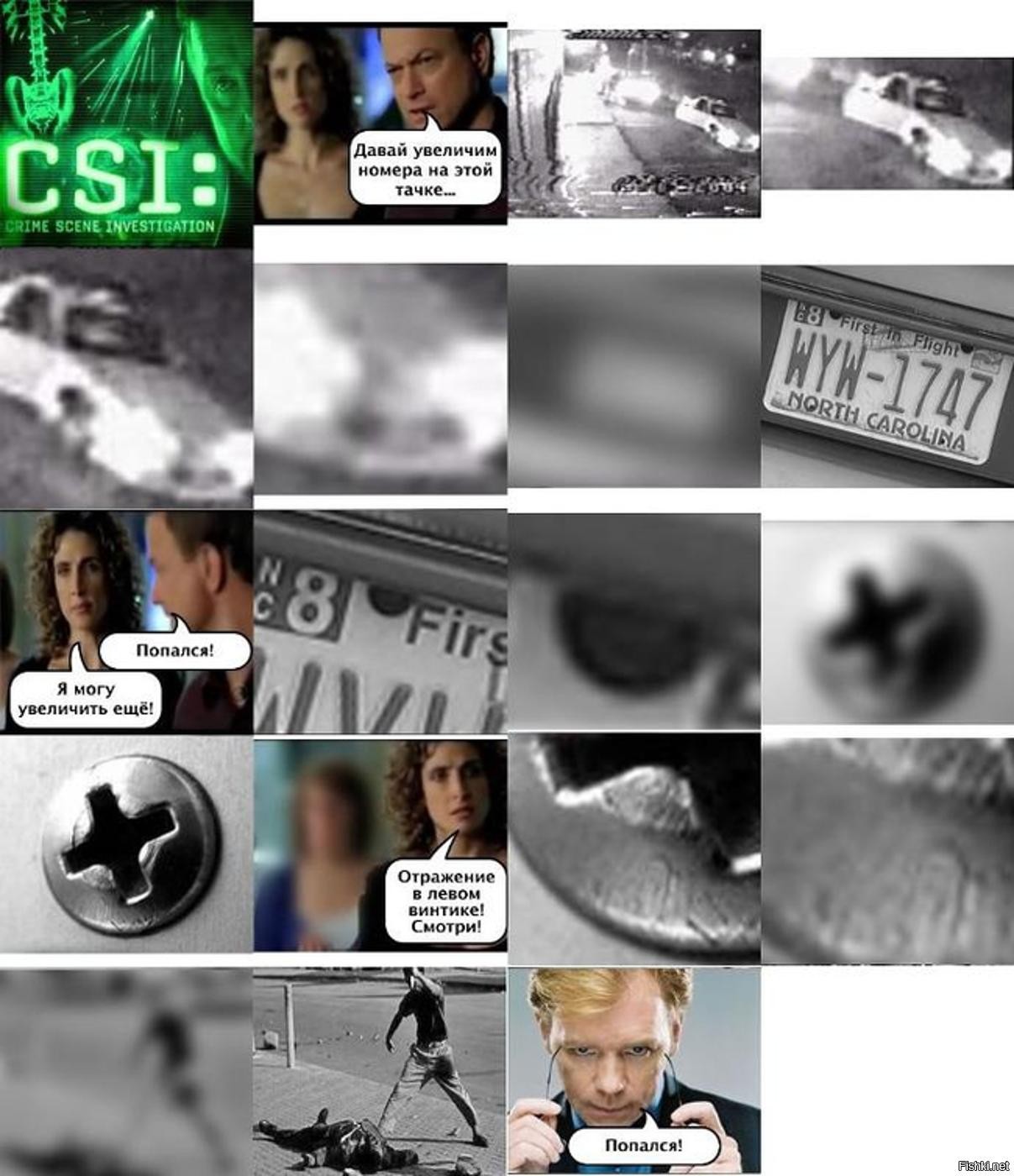
программа деблюрила автономера.
По одному котику на пиксель
есть великолепная сцена из фильма с Джоди Фостер.
"Контакт" хорош! 3а исключением того, что когда тетка вернулась, начали долгое нудное разбирательство про ее "религиозный опыт", вместо того чтобы запустить десяток теток и дядек следом, и проверить воспроизводимость. саму книгу не читал. К сожалению, подозреваю, что Саган это тоже написал.
Дело в том, что истина для них — дело десятое. Для чиновников — экономия денег налогоплательщиков, да и просто нежелание подрываться на лишние хлопоты. Для научных светил так и вовсе острое неприятие подрывов устоев, которые они всю жизнь возводили, и на которых теперь покоятся. Вспомним погибшего окодемика. Скептицизм, граничащий с ретроградством.
>>>
ОК.
Надо почитать книгу тогда. Она у меня есть, кстати, только я не могу книг читать, надо достать ПДФ
- Нет, просто не могу
- Безпдфовое...
Вышел Xiaomi Mix 4, первый с подэкранной камерой.
Было бы интересно, если бы вы поизучали и обзорчик ).
В нем много всего интересного.
Молодой человек протягивает мне фотку 9x12cm, сделанную явно “мыльницей”. В середине кадра, “издали похожая на муху”, группа людей. Он показывает на голову одного из группы и спрашивает: “Можете отсканировать так, чтобы только это лицо было, а остальное отрезать?”
– Легко, — говорю, — Только Вы себе представляете, какое это будет качество?
– А Вы, — говорит, — Улучшить не можете? Например, насытить лицо пикселями?

>>>Смех смехом, но если так начнут работать с фото при полицейских расследованиях...
хорошо что хоть Обаму отмазали. Не надо будет коленом душить около машины.
Проедпоследгий столбец - их алгоритм, последний - оригинал до уменьшения.

Или четырёх.
именно поэтому мне интереснее, когда умные люди идут работать не туда, где больше платят за херню (банковские "прогнозы", трейдинг за наносекунду, фейковые фотки и видео), а туда, где свой мозг можно приложить к решению сложных и важных проблем,.
Kлиматическое моделирование (какие-нить турбулентные потоки), новые аккумы, марсоходы, фьюжн, предсказание белков с "нуля" (пока, по-моему херня до-сих пор, как бы пыжились), и пр -- стопицот мест, где можно себя приложить. Нейросети май эсс: "мы и так ни хера не понимаем, как оно считает, но прикольненько выходит".
Повторю вновь – вы не можете создать то, о работе чего "вообще ничего не будете знать". Ну вообще никак не можете, ну просто по определению... ?
P.S. Поэтому, в общем-то, те или иные нейросети то и дело "корректируют" в нужную сторону. Как вы считаете, это "волшебство" какое-то – или, всё же, знание самих принципов работы своей сети? Вот и я о том же... ))
Вот для это и нужна "возня с нейросетями" – относительно приемлемый (даже на данных этапах) результат с высокой скоростью. То есть, по соотношению "результат/время" уделывает любого человека просто напрочь.
А что касается вашего вопроса про "указать прямо" – мешает отсутствие у нейросети "полного понимания" того, что именно она делает (потому, собственно, порой на выходе и получается сущая дичь))). Это мы представляем себе всю реальную "объёмность" фото или видео – а для нейросети это всего лишь двухмерный (!) массив пикселей разного цвета.
То есть, нейросеть вообще не оперирует понятиями "глаза", "волосы" или "блик" – для неё это всё в равной степени всего лишь абстрактные участки изображения, она ищет лишь формальную схожесть объектов и потом умело "отрисовывает" найденный результат сугубо технически.
Возможно, так будет понятнее...
Вот вы родились, и ходить не умеете. Зато у вас есть куча датчиков входной информации и penalty function в виде синяков и шишек. Далее нейросеть пытается экспериментировать с теми или иными сигналами, которые она подает на приводящие механизмы в виде мышц, возникает куча многомерных векторов и матриц для описания этих состояний, штрафы от падений, покуда не будет найдено оптимальное решение.
Турбулентные потоки? А какой смысл в мельчайших деталях копаться в том, что мы изменить не в силах? Гораздо полезнее "интегральные" данные, чтобы не размещать производства (пром или сх) в тех районах, где это противопоказано климатически. Аккумуляторы? Тогда уж лучше энергосберегающие средства, что и для климата полезнее.
Ну, и традиционный "черный ящик". Не знаем, как устроен, но умеем использовать результаты его работы.
Да что там ящики - просто ребенка сделать, "о работе которого..." (кто-то опередил)
Но это уже обычная голая схоластика, пардон.
Детей-то фактически "создаём" не мы, создаёт их природа (хоть мы и активно участвуем в процессе, ага)). А вот нейросети запрограммили именно мы, в них нет совершенно ничего "непонятного". Потому и можем в любой момент изменить любые (!) их настройки, аж вплоть до полной неузнаваемости (чего явно не скажешь о детях))...
Конечно же это метафора с ящиком.
Если что, то у меня в университетском дипломе специальность "вычислительная математика". Матанализ читал академик Скороход, написавший трёхтомник "Теория случайных процессов". Про нейроны и нейронные сети читал спецкурс дважды доктор наук - по математике и по биологии. Было это дохрена лет назад, но кое-что ещё помню.
Мир экзотики, конечно, полон чудес, да вот только в обычной жизни они не встречаются. А на практике даже адронные процессы в ЦЕРНе считают на решетке. И давайте не будем блохах, мне это неинтересно.
вы же вирусологи-эпидемиологи! )
Конечно же это метафора с ящиком.
То есть, "чёрный ящик" это исключительно с вашей (да и моей отчасти)) "пользовательской" точки зрения. С точки зрения же непосредственных разработчиков (которые, внезапно, обычные люди, а вовсе не какие-то там инопланетяне)) – этот ваш "ящик" практически прозрачный.
Вот и с нейросетями точно так же. Всё ж просто... ?
Так что именно помните-то, имеющее непосредственное отношение к теме нашей дискуссии и опровергающее мои утверждения? Особенно любопытно с учётом того, что уж "коллега" математик-то точно должен знать, что не бывает на свете никаких формул и законов в виде "чёрного ящика" – бывают максимум без чётких доказательств (что, впрочем, нисколько не мешает применять их в прикладной работе).
Действительно интересно. Поскольку моё "смежное" с вашим образование (из которого, впрочем, тоже всю "непригодившуюся" сугубо математическую часть уже практически забыл через четверть века))) – уже более чем допускало наличие систем, подобных нынешним нейросетям.
То есть, ещё аж в начале девяностых нам прямо говорилось о гипотетическом (тогда ещё) экспоненциальном росте сложности ПО, в котором будет всё труднее и труднее разбираться "непосвящённым" (сложнее сугубо физически в буквальных "человеко-часах", но никак не теоретически, о чём зачем-то упорно говорите вы))...
Метод кодирования звука в цифру прекрасно известен, метод декодирования также прекрасно известен. Аналоговая часть (неизбежная в данном случае) работает лишь на самом последнем, конечном участке всей этой достаточно длинной цифровой цепочки – как, например, тот же самый дисплей, отображающий нам конечные результаты работы нейросети.
То есть, вновь никаких "чудес"... ?
P.S. Не, ну можно, конечно, вспомнить ещё и про "аналоговые" физические процессы непосредственно в самом оборудовании – но это будет совсем уж мелочно... )))
Умер композитор который написал "сиртаки". Настолько популярная композиция что многие во всем мире думают что это народная греческа музыка и танец ,но нет. Это продукт гениальности великого Микиса Теодоракиса.
Как-то заказывал проспект у наших лоховских дезигнеров на ставке (непонятно, зачем их держат вообще, лучше бы починили воду в лабе), надо было показать, как из пиксельной картинки получается координата. Oни написали: "чо такая картинка пиксельная, другой нет что ли? И вообще мы, типа, заняты, через 2 недели будет. "
Я им написал вежливое "тогда идите нах, занятые и умные такие", и распечатал в обычной конторе -- вопросов умныx не задают и делают за ночь. Мне легче стольник заплатить, чем с дaрмоедами общаться.
А если серьёзно – "3D восстановление исходной сцены" просто невозможно в случае с обычным фото. Мы ведь элементарно не знаем, что находится за пределами кадра – и высчитать это совершенно никак невозможно. Соответственно, мы не можем точно установить ни источники освещения объекта, ни источники бликов-отражений.
Я уверен, что улучшайзинг будет гораздо лучше через несколько лет. Но одной сетки, помнящей похожие самплы, явно мало. Нужно еще что-то вроде метода трассировки лучей, только наоборот.
Точнее, не знаете всех источников – наша память на многие порядки менее детальна. Плюс в освещении участвуют как первичные (прямые), так и вторичные (отражённые) источники света – высчитать это всё вы тоже не можете. И точно высчитать даже отражение на какой-нибудь выпуклой (или "впуклой")) отражающей поверхности вы тоже не можете.
Но хорошо, если даже вытягивать информацию "тупо с фото вокруг" (что, кстати, используется, но в иных целях)). Вы теперь на каждое фото будете делать по несколько десятков снимков ещё и вокруг? "Подожди, дорогая, попозируй ещё на фоне заката, мне надо сделать ещё двадцать фото вокруг тебя!". ))) Или как, или что?
Мне непонятна суть вашего "возражения", серьёзно. ?
Ну простейший ведь факт. Вот вы смотрите нашими "стерео-глазами" на объект. Вы сможете точно и достоверно определить, что именно и откуда именно его освещает, и что именно объект отражает – не видя вообще ничего за пределами определённой "рамки"? Во-о-от, то-то же ж... ?
P.S. Про остальные моменты написал комментарием ранее.
О коде, который сами же написали – и который можем в любой момент изменить??? Или вы тоже забыли, что мы можем крутить-вертеть практически любые параметры нейросети, регулируя конечный результат?
Простите, но, по-моему, вы явно имеете достаточно мало знаний (но достаточно большой багаж мифов) как непосредственно о самом предмете дискуссии, так и об IT-отрасли в целом...
Понимаете, невозможно написать код, который работает "неизвестно как". Если вдруг в ПО (любом!) вообще появляются моменты "неизвестно как" – значит, это либо временный баг, либо программист тупо писал его по бухе и сам забыл собственные решения и "озарения". Третьего тут просто не дано. ?
• Голограммы – множество (!!!) самых обычных 2D-проекций (для примера см. хоть знаменитый кинематографический приём Bullet time))).
• Томограф – множество (!!!) самых обычных 2D-снимков, просто на разную глубину действия для их последующего "послойного" объединения.
Повторю, всё просто – чудес не бывает. Из недостаточной информации вы никак не вытащите полную – максимум "дискретно-кусочками"... ?
Есть, конечно, "настоящие" 3D-сканеры (и даже довольно давно) – но там и качество оставляет желать лучшего (даже сегодня, увы), да и с последующим текстурированием полученных моделей тот ещё геморрой. То бишь, пока вариант "просто прикольная приблуда", по большей части. Да и сканировать умеют лишь "внутрь себя" (то есть, габариты сканируемых объектов достаточно ограничены), но никак не наружу (просветите уж, если вы в курсе об обратном))).
Одним словом – рекомендую сначала изучить суть вопроса, а только потом спорить. Мне всегда помогает. Вам тоже поможет, уверен...
password
123456
maga2020
Дорисовывает. У стариков будет меньше морщин, а у молодых больше.
Бабло платят, живут в Бей Эрии, красота. Занялись бы чем-то более полезным. Прогнозом погоды или моделированием климата, например.
А 30 лет назад один айфон обсчитал бы быстрее, чем все компы в мире. "никто не сказал, что будет легко".
Какой такой айфон тридцать лет назад, имя, фамилия, должность?
Тридцать лет назад были разные Креи и прочие супер-пупер компы. Сомневаюсь, что даже сегодняшний афон обгонит Крей тех лет, и что в нем есть плавающая 64-разрядная арифметика.
2) Подсчет прогноза с точностью в несколько сотен метров для многодневной крейсерской регаты - это замечательно. Для олимпийской регаты? Ну, дождемся уточнений по п.1.
3) "Несколько сотен" - это ужасно звучит для человека со специальностью "вычислительная математика". Патамушта и две, и три, и двадцать три сотни - это все "несколько". Понятна зависимость результата от природных условий и точности измерений показателей, но тогда говорят - "от двухсот до семисот", или еще как.
Вообще все эти алгоритмы сжатия по определению - сжатие с потерями. Вся инфа которая "потерялась" - она не восстанавливается никак. Любой самый умный алгоритм будет вносить отсебятину, которая может быть некритичной (восстанавливаем фотки с выпускного) или критичной (по восстановленной фотке ловим преступника).
Но стоит скормить им действительно малорарзмерное или изначально нечёткое изображение - усё, фиаско.
Тот же упомянутый ранее в теме Gigapixel AI (или Sharpen AI, или JPEG to RAW AI, всё от одного производителя) – достаточно неплохо "вытягивают" большинство скормленных им низкокачественных, и/или запоротых, и/или слишком пережатых изображений (для каждого варианта есть как готовые пресеты, так и тонкая ручная настройка). Бывают, конечно, случаи, когда "медицина бессильна" – но таких примерно не больше четверти, по своему опыту...
Поэкспериментируйте. У них на сайте есть бесплатные триалы на месяц (насколько помню) – времени на "пощупать" хватит... ?
P.S. Я вот как раз замахнулся на "ремастеринг" одного любимого старого фильма. Там качественных исходников в принципе никогда не было, плюс все копии в сети ещё и страшно пережаты кодеками. Но по предварительным экспериментам на отдельных кадрах – вполне себе так недурственно апскейлится вплоть до 1080p...
-- а зачем
затем, не ваше дело
-- профессионально апскейлить
данная технология вообще не имеет ничего общего со словом профессионально, в коммерческой сфере, где прям важен результат она неприменима
-- сотруднику мака
дайте исчерпывающий список мест работы, где можно заниматься улучшайзингом фото, а где нет, раз уж вы все за всех решили
И дело не в этой программе конкретно, и не в этой должности тоже. Просто факт, что соотношение софт-зарплата конкретно для России довольно непропорционально. Неприятно, когда обычных людей называют нищими только потому, что в других странах другие деньги.
Я вам намекну, но вы не поймете, но для жизни и работы в данной реальности "обычной звонилки" недостаточно. Точка входа в работу хоть курьером, хоть грузчиком начинается со смартфона с приложением и андроидом версии от 10 и выше. И если работа на целый день, то и с аккумулятором от 4000 mAH или с пауэрбанком.
Возвращаясь к моему сферическому студенту, просто купить легально весь софт, который так или иначе нужен для учебы и работы - это год бесплатно трудиться.
В гугле есть исходники всех картинок, делов то, по ужатой копии найти и показать оригинал.
За денюшку.
Скажу правду как есть.
Поскольку Гугл собрал исходники "реального мира", им нетрудно получить доступ к любым произвольным данным с требуемой точностью.
"Матрицу" посмотрите, неверящие!
$color = imagecolorallocate(rand(0, 16777216));
draw(0, 0, 1, 1, $color);
Не, на самом деле круто, конечн.
- Мы что, в американском фильме? Я могу лишь с контрастом играть.
Французский фильм "Шесть"
Или фото если человек не может по плохому определить?
ну скажем XYZQ 77 88
Которых физически нет на исходном фото?
Софт их из головы должен выдумать?

А вообще есть же полно программ для криминалистики, будет плюс ещё дофига.